Multi-Class Text Classification
Text multi-class classification project exploiting different
techniques for vector representation of text and models.
Introduction
The aim of this project is to build a model that is able to assign to a document one of the following 9 classes: Agent, Place, Species, Work, Event, SportsSeason, UnitOfWork , TopicalConcept, Device. The data set used to train and test our models contains 342,782 wikipedia articles and it can be downloaded here. All the models I'm going to use for the classification step require continous explanatory variables, but in this case the only variable that we have at disposal is the text of the document. In order to solve this problem we can represent text or words of each documet as a numerical vector and this technique is called word embedding. Let's see how our target value is distributed.
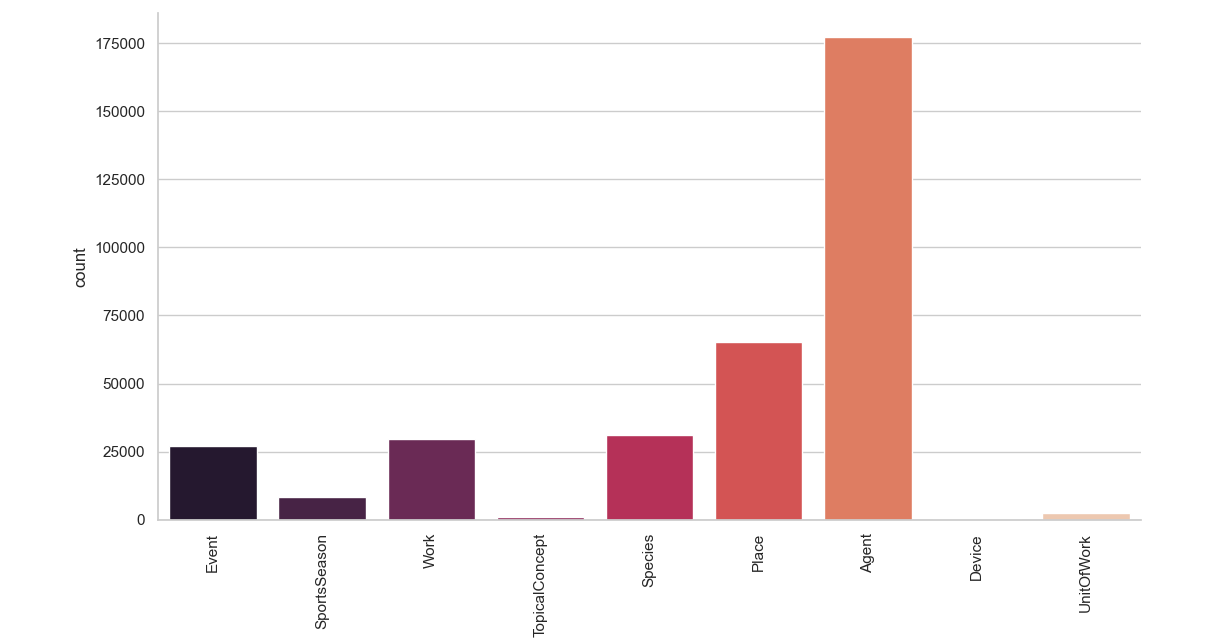
We are in the case of an unbalanced data set, meaning that we have an unequal distribution of our classes. This might be a problem for our models, so we have to keep in mind this fact if we spot something strange in our classification.
Data Cleaning
One important step when we deal with textual data is the data cleaning process, basically it aims to delete all the elements of a document that are not useful for the analysis. Let's take a look how our documents look with an example:
As we can see our text is full of elements that are not going to improve our classification such as numbers and stopwords. Another good thing to do is to trasform all letters into lowercase. Let's see how our documents have changed.
Now it looks much better and we are done with text pre-processing
1. TF-IDF
As discussed in the introduction we have to change how the text of the documents is represented. In order to do so we can build vectors based on the term frequency–inverse document frequency (TF-IDF). This statistic evaluates how relevant a word is to a document in a collection of documents (corpus). The numeric vectors that represent each document in our corpus are made of the TF-IDF statistics computed for each word and document. I considered different models to perform the classification and a brief explanation of them is provided below.
Linear support-vector machine
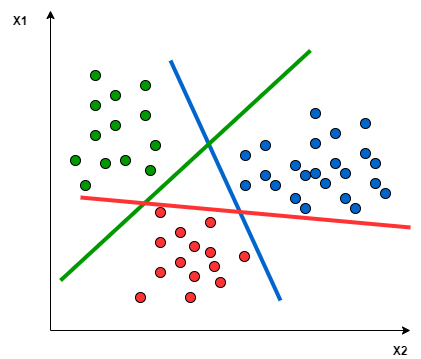
SVMs are based on finding the "best" hyperplane that in a n-dimensional euclidean space is able to split two classes of a given dataset. By "best" I mean the hyperplane that is able to maximize the distance between the support vectors and the hyperplane itself. The support vectors are the closest points from both classes to the hyprplane. The following picture gives a more clear insight on how the hyperplane is defined in a very simple case, where we just have two explanatory variables and the hyperplane is a line.

SVMs don't support multi-class classification natively, but there are different approaches that solve this problem. The function LinearSVC from the scikit-learn package implements by default the One-vs-Rest approach that is based on splitting the multi-class dataset into multiple binary classification problems. An hyperplane is constructed for each class and each hyperplane separates the points of a the given class from the points of the remaining classes. The way this hyperplanes are defined is equivalent to the two classes case discussed above. The picture below shows a graphical representation of the hyperplanes in the case where we have only two explanatory variables
Logistic Regression
Logistic regression as SVMs doesn't support multi-class classification natively. The One-vs-Rest approach can be again implemented, in this case it is based on training a logistic regression classifier for each class and then compute the conditional probability of belonging to the corresponding class given our data. The observation is then assigned to the class that maximizes this probability.
multinomial naive bayes
This model as the previous one is based on finding the class that maximizes the conditional probability of belongig to it given our data. The difference originates from how this probability is computed. Its computation is based on the bayes theorem and on the conditional indipendence between the feautures, that in our case are represented by the term frequencies–inverse document frequencies of words in each document. Below it is shown how the conditional probability of observing the k-th class, given the term frequencies–inverse document frequencies, is computed.
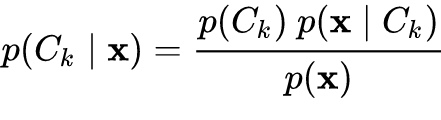
Random forest
Random forest is an ensamble approach based on grouping weak-learners (decision trees) providing a strong learner that is able to give more stable and accurate predictions. Basically we build a predefined number of trees considering for each of them a random subsample of our dataset. At each node m features selected at random are used to perform the binary split that maximizes the homogeneity of the target variable within the subsets created after the split. Each observation is classified according to the class that obtains the most number of votes by the random trees. The picture below shows the intuition behind this technique.
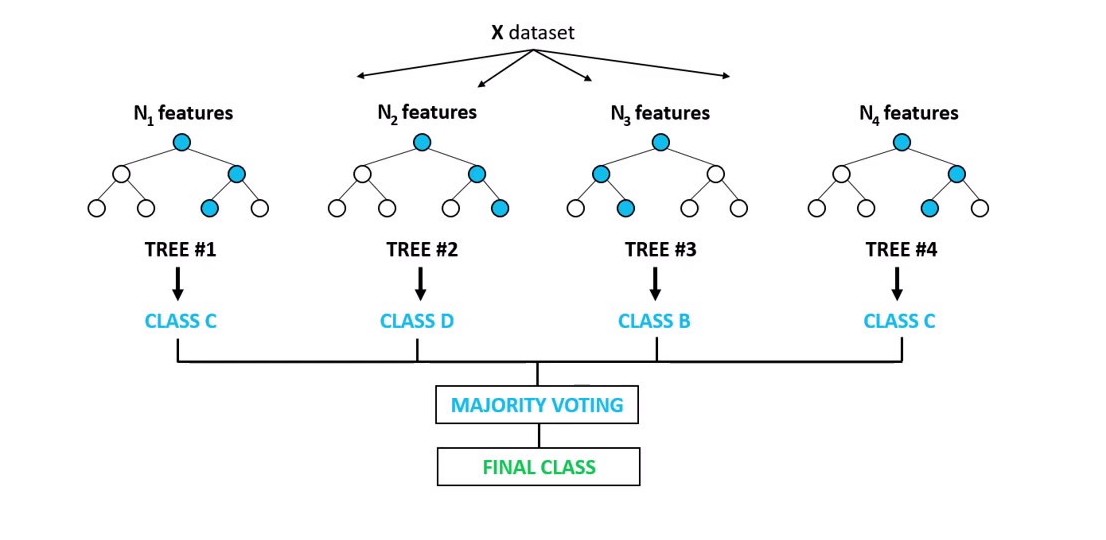
In this case I set a maximum depth of the trees equal to five, meaning that the length of the longest path from a root to a leaf is five and considered 100 trees.
The results of the analysis are shown below
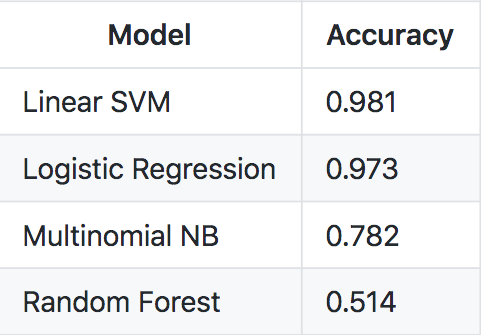
As we can see the best result in terms of accuracy is given by LinearSVC, also LogisticRegression performs really well and it is interesting how such simple models that are so inexpensive to train are able to predict our target variable so easily. Surprisingly RandomForestClassifier performs poorly, probably we can improve this model by changing its hyperparameters, but I don't think we are able to produce a nice result as the ones given by LogisticRegression and LinearSVC. Let's now try to get more insights by looking at the confusion matrix produced bt the linear SVM model

As we can see a great proportion of the observations is in the main diagonal of the confusion matrix, meaning that they are correctly classified. We can notice also that most of the documents that are misclassified come from the column of predicted documents as "agent" and the row of actual "agent" documents. The pattern that can be spotted in this column can be explained by the fact that we have an imbalanced data set, most of our documents are labeled as agent, so the model tends to be attracted by this class when making predictions even if an a mild way.
2.1 Embedding layer and Artificial neural networks
The embedding layer enables us to represent the words of our vocabulary as vectors. It is an improvement of representing each word using one-hot encoding because it produces dense low-dimensional vectors. Another interesting feature is that this word embeddings are not fixed as in the one-hot encoding case, in fact they are uptaded while training the neural network, that in this case deals with a classification problem.
The documents have different lengths so in order to have vectors of the same length we use pad_sequences(). We also fix a max length for the documents equal to 100. Now the previous document looks like this. The Embedding layer is the first layer of our neural network and requires integer coded data as input, so each word has to be represented as an integer. For this analysis we want to consider just the 10000 most frequent words in our corpus. Now the first document in our data set looks like this. As we can see as the indexing decreases, the frequency of the word in our corpus increases.
Now we are ready to define our model:
Below it is shown the output from the output layer for a given document.
As we can see the first element of the vector has the highest value, so the document is going to be classified to the first class. The confidence level is also very high so we are making a reliable prediction.
We can see that the prediction is correct.
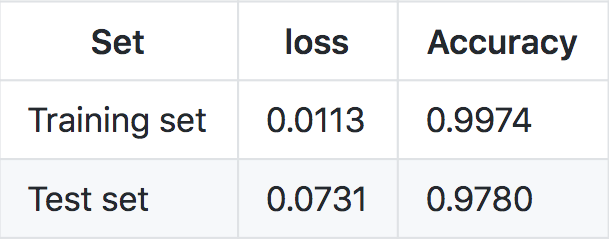
As we can see the model makes very accurate predictions, but still it is worse compared to linear SVM.
Embedding layer and recurrent neural networks (LSTM)
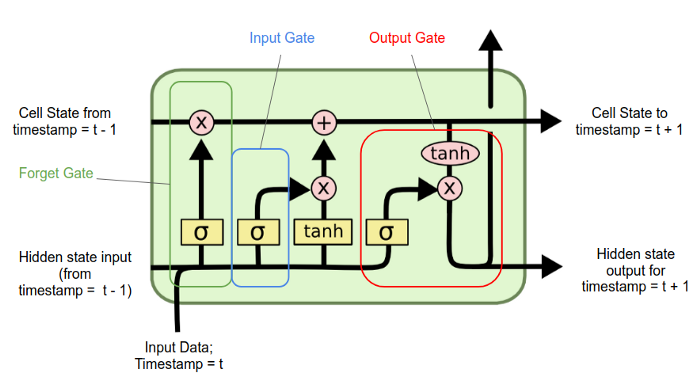
We can improve the previous model by trying to add context to word vectors and this can be done by using recurrent neural networks. Traditional neural networks all inputs as independent, but this doesn’t make much sense if those inputs represent words in a document. RNNs are able to connect previous information to the present task. The traditional RNNs however aren’t able to handle long-term dependencies, so when gap between the relevant information and the point where it is needed is large. Long Short Term Memory networks (LSTM) are a special case of RNNs that are able to handle long-term dependencies. One import element is the cell state that represents the memory of the LSTM and can be updated by forgetting or adding information. As all RNNs they have a chain structure of repeating cells. Each cel has 4 interacting neural network layers and can splitted into 3 gates:
The only difference from the previous model is the fact that I added the LSTM "layer" and increased the number of epochs to 5, because it seems to take more time to converge. Below you can find the results.
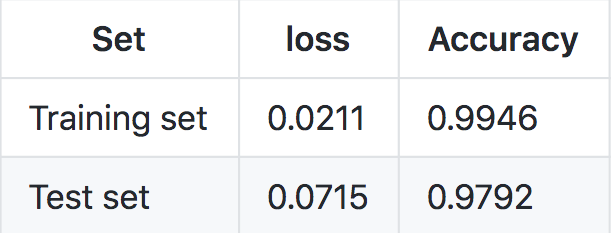
As we can see we got a slightly better result with respect to the previous model but at a big expense, the model takes a lot more time to train.
Pre-trained Word Embeddings
Pretrained Word Embeddings are the embeddings learned in one task that are used for solving another similar task that in this case it is classifying documents. When we built the embeddig layer in the previous paragraph, its weights were randomly initialized. One thing we can do is to use the pretrained word embeddings learned in a large data set instead of the randomly initialized ones. I used Stanford's GloVe pre-trained word embeddings that can be downloaded here. Below we have the results
Unfortunatly providing a smart initialization of our model didn't helped with improving our result.
Conclusions
We managed to build computationally inexpensive models that are able to produce very accurate classifications. It interesting how we can solve such a complicated problem in just few minutes. The complex and sophisticated LSTM model wasn't able to beat the simple SVM model.